理解爬虫软件的基本概念
爬虫软件是一种自动化工具,用于从互联网上抓取公开数据,在安装和使用这类工具前,需明确其合法性和合规性,合法爬取的前提是遵守目标网站的robots.txt协议,尊重数据隐私,避免对服务器造成过大负载,本文将以Python环境为例,介绍如何安装和配置开源爬虫框架Scrapy,帮助用户高效且合规地完成数据采集。
准备工作:环境与工具选择
1、安装Python环境
爬虫软件通常依赖编程语言环境,Python因其丰富的库和简洁语法,成为主流选择。
- 访问Python官网下载最新稳定版本(推荐3.8以上)。
- 安装时勾选“Add Python to PATH”,确保命令行可直接调用。
- 验证安装:打开终端输入python --version,若显示版本号即成功。
2、选择适合的爬虫框架
Scrapy:适合中大型项目,支持异步处理、自动重试等高级功能。
Requests + BeautifulSoup:适合轻量级需求,学习成本较低。
本文以Scrapy为例,因其扩展性强且符合企业级开发规范。
安装Scrapy框架的详细步骤
1、配置虚拟环境(可选但推荐)
为避免依赖冲突,建议使用虚拟环境隔离项目。

# 安装virtualenv库 pip install virtualenv # 创建并激活虚拟环境 virtualenv scrapy_env source scrapy_env/bin/activate # Linux/Mac scrapy_envScriptsactivate # Windows
2、安装Scrapy
在激活的虚拟环境中执行以下命令:
pip install scrapy
安装完成后,输入scrapy version,若返回版本信息(如Scrapy 2.8.0),则说明安装成功。
3、处理常见安装问题
依赖缺失错误:部分系统需额外安装依赖库,在Ubuntu/Debian中运行:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev libssl-dev权限问题:在命令前添加sudo(Linux/Mac)或以管理员身份运行终端(Windows)。
配置爬虫项目的关键要点
1、创建Scrapy项目
通过命令行生成项目结构:
scrapy startproject my_crawler cd my_crawler
生成的目录包含spiders(存放爬虫脚本)、items.py(定义数据结构)等文件。
2、编写第一个爬虫脚本
在spiders文件夹中新建文件example_spider.py,示例代码如下:
import scrapy
class ExampleSpider(scrapy.Spider):
name = "example"
start_urls = ["https://example.com"]
def parse(self, response):
title = response.css("h1::text").get()
yield {"title": title}此代码抓取目标网站首页的标题文本。
3、设置请求参数与伦理规范
延迟请求:在settings.py中设置DOWNLOAD_DELAY = 2,避免高频访问。
遵守robots.txt:确保ROBOTSTXT_OBEY = True(默认开启)。
User-Agent标识:修改默认UA,标明爬虫身份便于网站管理员联系。
运行与测试爬虫
1、启动爬虫并保存结果
执行以下命令运行脚本,并将结果输出到JSON文件:
scrapy crawl example -o output.json
若看到类似DEBUG: Crawled (200) <GET https://example.com>的日志,说明抓取成功。
2、验证数据完整性
打开生成的output.json文件,检查是否包含预期内容。
{"title": "Example Domain"}3、错误排查方法
403禁止访问:检查目标网站反爬策略,尝试更换IP或添加请求头。
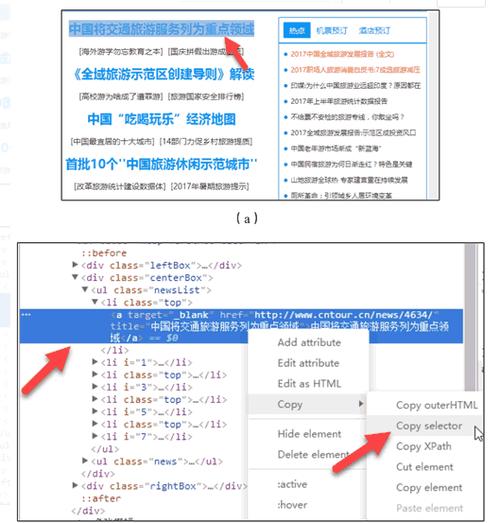
数据提取失败:使用Scrapy Shell(scrapy shell URL)实时调试CSS/XPath选择器。
提升爬虫效率与合规性
1、异步与并发优化
Scrapy默认基于Twisted库实现异步请求,可通过调整CONCURRENT_REQUESTS参数提升并发数,需注意:过高并发可能导致IP被封禁。
2、代理与分布式部署
针对大规模采集需求,可使用:
代理IP池:解决IP限制问题,推荐付费服务保障稳定性。
Scrapy-Redis:实现分布式爬虫,提升任务调度效率。
3、定期维护与日志监控
- 记录爬虫运行日志,分析异常频率。
- 更新选择器代码,适配目标网站改版。
关于技术伦理的思考
数据采集的便利性伴随责任,使用爬虫软件时,需始终保持对数据来源的尊重:不抓取敏感信息,不破坏网站正常服务,避免将数据用于非法用途,技术本身无善恶,但使用者的选择决定其价值。







评论列表 (0)