从零开始构建高效工具
在当今数据驱动的时代,爬虫技术已成为获取网络信息的重要手段,无论是学术研究、市场分析还是个人项目,掌握爬虫开发技能都能极大提升效率,本文将系统讲解如何从零开始构建一个合规、高效的爬虫工具,同时结合行业规范与技术要求,确保开发过程符合主流平台规则。
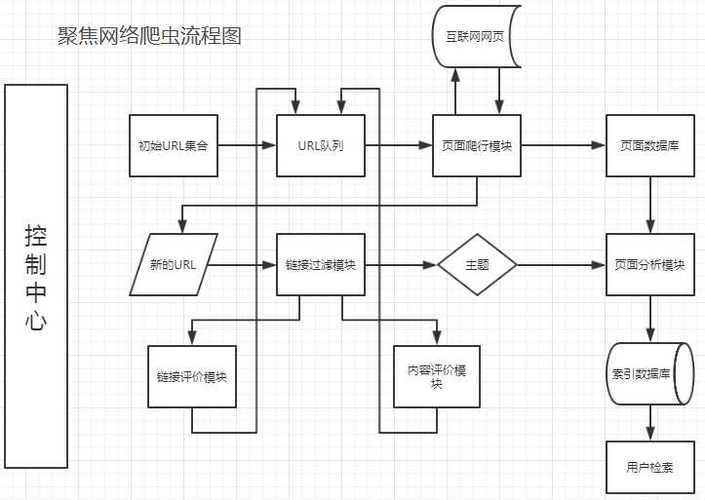
**一、理解爬虫的基本原理
爬虫(Web Crawler)本质是一种自动化程序,通过模拟用户行为访问网页,提取并存储所需数据,其核心流程分为四步:
1、目标分析:明确需要抓取的网站及数据类型(如文本、图片、链接)。
2、请求发送:通过HTTP协议向目标服务器发送请求,获取网页原始代码。
3、数据解析:从HTML、JSON等格式中提取结构化信息。
4、存储与管理:将数据保存至本地或数据库,并进行去重、清洗等处理。
开发前需掌握基础编程知识(如Python、Java),熟悉HTML结构及网络协议(如HTTP/HTTPS)。
**二、选择适合的开发工具与框架
1、编程语言推荐
Python:语法简洁,生态丰富,适合快速开发,常用库包括:
Requests:处理HTTP请求。
BeautifulSoup/lxml:解析HTML/XML内容。
Scrapy:全功能爬虫框架,支持异步处理与分布式部署。
JavaScript:适用于需要模拟浏览器行为的场景(如动态加载页面),可使用Puppeteer或Selenium。
2、辅助工具
数据库:MySQL/MongoDB用于存储结构化或非结构化数据。
代理IP服务:防止IP被封禁,提升抓取稳定性。
日志监控系统:实时跟踪爬虫运行状态,及时处理异常。
**三、开发流程详解
**步骤1:分析目标网站结构
- 使用浏览器开发者工具(F12)查看网页元素,确定数据位置。
- 检查Robots协议(目标网站根目录下的robots.txt),确保抓取行为合规。
**步骤2:发送HTTP请求
- 通过Requests库发送GET/POST请求,需设置合理请求头(Headers),包括User-Agent、Cookie等,模拟真实用户访问。
- 示例代码:
import requests
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get('https://example.com', headers=headers)- 使用XPath或CSS选择器定位元素:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.select('h1.main-title')[0].text- 动态页面处理:若数据通过JavaScript加载,需借助Selenium控制浏览器渲染。
**步骤4:数据存储与优化
- 将数据存入CSV、Excel或数据库,建议按字段分类存储。
- 使用增量爬取(记录已抓取URL)避免重复采集,节省资源。
**四、规避风险与伦理规范
1、遵守法律与平台规则
- 禁止抓取个人隐私、版权保护内容。
- 控制请求频率(如每秒1-2次),避免对目标服务器造成负担。
- 遵守《网络安全法》及国际GDPR等数据保护条例。
2、反爬策略应对
验证码识别:接入第三方OCR服务或机器学习模型。
IP限制:使用代理IP池轮换请求地址。
请求头伪装:随机切换User-Agent、Referer等参数。
**五、常见问题与解决方案
1、数据乱码
- 检查网页编码(如UTF-8、GBK),使用response.encoding属性修正。
2、连接超时
- 设置重试机制(如Retry库),添加超时参数:
response = requests.get(url, timeout=10)
3、反爬升级
- 模拟鼠标移动、滑动验证等行为(需配合Selenium)。
- 使用无头浏览器(Headless Chrome)绕过检测。
**六、提升爬虫效率的技巧
多线程/异步处理:利用Scrapy的Twisted框架或Python的Asyncio库。
分布式架构:通过Redis实现多节点任务调度。
缓存机制:对静态资源(如CSS、JS文件)进行本地缓存,减少重复下载。
**个人观点
爬虫技术的核心价值在于将无序数据转化为结构化信息,但其应用必须建立在合法合规的基础上,开发者需始终以尊重数据所有权为前提,平衡效率与伦理,建议在实际项目中优先选择官方API接口,若必须使用爬虫,则严格遵守目标网站的规则,避免滥用技术,技术的进步不应成为破坏网络生态的工具,而应服务于更高效、更智能的数据应用场景。








评论列表 (0)