预测软件作为结合数据分析与算法应用的工具,在金融、气象、商业等领域均有广泛需求,制作一款实用的预测软件不仅需要编程能力,更考验对业务逻辑的理解与数据处理技巧,以下是制作预测软件的核心步骤与关键要点,供开发者参考。
第一步:明确需求与目标
开发预测软件前,需清晰定义软件的应用场景,是用于股票价格预测、用户行为分析,还是销量趋势判断?不同场景对数据源、算法精度及输出形式的要求差异显著。
确定输入输出:明确用户需要输入哪些参数(如历史数据、实时变量),输出结果以何种形式呈现(如数值、图表、概率区间)。
性能指标:设定误差范围、响应速度等标准,例如金融预测软件需毫秒级响应,而气象预测可接受分钟级延迟。
第二步:数据收集与预处理
数据质量直接影响预测结果,需从可靠渠道获取结构化或非结构化数据,如公开数据库、API接口或企业自有系统。
清洗数据:剔除重复值、异常值,处理缺失数据(如用均值填充或直接删除无效样本)。
特征工程:提取关键变量,在电商销量预测中,需考虑季节因素、促销活动、竞品价格等。

第三步:选择算法与模型构建
根据需求选择合适算法:
时间序列预测:ARIMA、Prophet适用于具有周期性变化的数据(如月度销售额)。
机器学习:随机森林、XGBoost擅长处理多变量非线性关系,例如用户流失预测。
深度学习:LSTM神经网络适合处理高维度时序数据,如股票价格波动。
建议先用Python的Scikit-learn、TensorFlow等库快速验证模型效果,再针对业务需求优化参数。
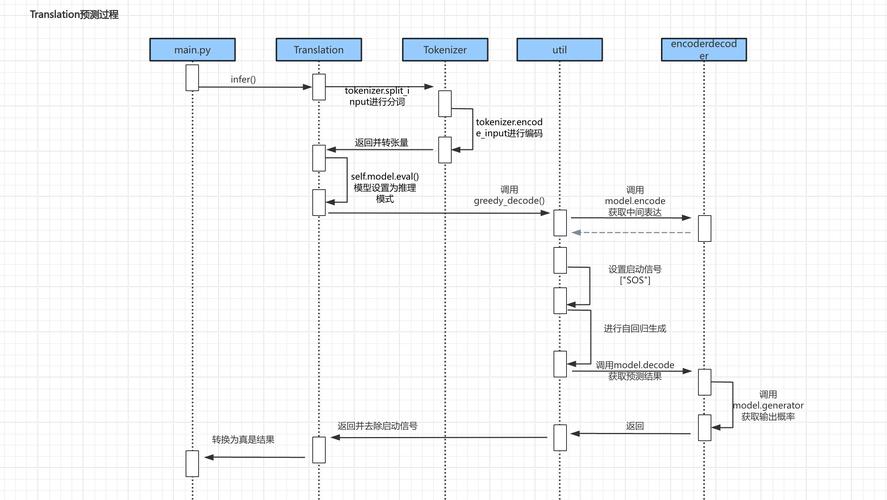
第四步:开发与测试
将模型集成到软件框架中时,需注意以下细节:
接口设计:提供API或可视化界面,降低用户操作门槛,金融预测软件可支持Excel插件导入数据。
实时性优化:通过缓存机制、分布式计算提升处理速度,使用Redis缓存高频访问数据。
测试用例:分阶段验证功能,单元测试检查算法准确性,压力测试评估系统负载能力。
第五步:部署与迭代
部署阶段需确保软硬件环境兼容,若为本地化部署,需提供安装包与配置文档;若为云端服务,需关注容器化(如Docker)与资源弹性扩展。
用户反馈:通过埋点收集用户行为数据,分析高频使用功能与潜在问题。
模型更新:定期用新数据训练模型,避免因市场变化导致预测失效,疫情后消费习惯改变,需重新调整零售预测参数。
关键注意事项
1、避免过拟合:训练集与测试集需严格分离,交叉验证可帮助评估模型泛化能力。
2、解释性需求:部分领域(如医疗预测)需提供模型决策依据,可采用SHAP、LIME等可解释性工具。
3、合规性:涉及用户隐私的数据需脱敏处理,并符合GDPR等数据保护法规。
预测软件的核心价值在于将抽象数据转化为可执行的决策建议,开发者需平衡技术复杂性与用户体验,避免陷入“技术完美主义”陷阱,一个准确率85%但能快速落地的模型,往往比追求95%准确率却延迟上线的方案更有实际意义,随着AutoML等自动化工具的普及,预测软件开发的效率将进一步提升,但对业务逻辑的深度理解仍是不可替代的竞争力。








评论列表 (1)
入门到精通,解析预测软件开发全程:从基础概念、工具选择至实战应用与优化的全方位指南。
2025年10月14日 18:39