随着数据获取需求日益增长,采集软件成为许多用户关注的工具,如何从零开始制作一款实用的采集软件?本文将从开发思路、技术实现到合规性要求,系统讲解完整流程,帮助读者理解核心逻辑。
一、明确需求与目标场景
开发前需明确软件用途,是用于电商价格监控、新闻聚合,还是社交媒体数据分析?不同场景对数据抓取频率、解析精度要求差异较大,以电商为例,需考虑反爬机制应对策略;新闻类则需关注实时性,建议用流程图梳理用户行为路径,确定功能优先级。
二、技术选型与工具准备
基础开发工具推荐Python(Scrapy框架)或Node.js(Puppeteer库),两者均有成熟生态,动态页面处理优先考虑Selenium,静态页面可用Requests+BeautifulSoup组合,数据库建议MySQL存储结构化数据,MongoDB处理非结构化内容,开发环境配置需注意代理IP池搭建、请求头随机化设置。
三、核心功能模块开发
1、数据抓取层:通过模拟浏览器行为或API调用获取原始数据,关键点在于设置合理延时(建议2-5秒)、自动切换User-Agent、异常重试机制。
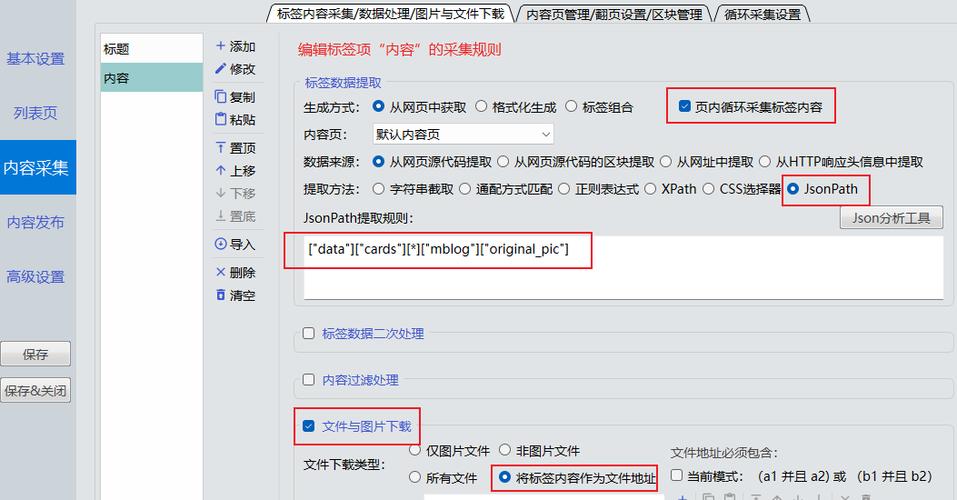
2、数据解析层:XPath或正则表达式提取目标字段,建议加入容错处理,防止网页结构变动导致程序中断。
3、数据存储层:设计标准化字段格式,添加时间戳与来源标记,注意数据去重设计,可采用MD5哈希校验。
4、可视化界面(可选):PyQt或Electron框架构建操作面板,集成任务调度、日志查询功能。
四、合规性设计与风险规避
严格遵守《网络安全法》和《数据安全法》,开发时需注意:
- 读取robots.txt文件并遵循爬取规则
- 设置单日抓取量阈值(建议不超过目标网站总数据量5%)
- 用户隐私数据过滤机制,如自动屏蔽手机号、身份证号
- 提供数据删除接口,响应合法数据删除请求
五、测试优化与部署
单元测试重点验证反爬策略应对能力,压力测试模拟多线程并发场景,优化方向包括:
- 采用异步IO提升吞吐量
- 分布式架构设计实现横向扩展
- 智能解析算法减少人工规则维护
部署时可选择Docker容器化方案,便于环境迁移与版本管理。
六、持续维护与迭代
建立异常监控系统,对HTTP状态码、解析失败率等指标设置报警阈值,定期更新UA数据库,维护代理IP可用性,建议每月进行安全审计,及时修复漏洞。
个人观点:技术实现仅是基础,开发者更应关注数据伦理,优秀的采集软件应在效率与合规间取得平衡,真正为用户创造可持续价值,工具本身无善恶,使用者的法律意识与道德准则才是关键。








评论列表 (1)
制作高效的采集软件需考虑需求分析、功能设计、数据结构优化、代码编写规范等多方面,以下是一份详细的制作教程,涵盖从零到一的全过程。
2025年06月26日 00:15