在当今数字化学习场景中,听写软件的需求持续增长,无论是语言学习者、教育从业者还是内容创作者,对高效、准确的听写工具都表现出强烈兴趣,开发一款实用的听写软件需要系统性规划与精准技术实现,以下从实践角度解析关键步骤。
核心功能定义需精准定位用户场景
软件功能设计必须围绕目标群体的核心痛点展开,以语言学习场景为例,用户往往需要支持多国语言识别、发音评估反馈、错误标记功能;而商务会议场景则更注重实时转写准确率、专业术语库支持,开发前需通过问卷调研、竞品分析明确用户画像,确定软件应具备的差异化功能,例如某外语培训机构定制的听写工具,通过收集教师反馈后增加「错题自动归档」功能,使学员重复训练效率提升40%。
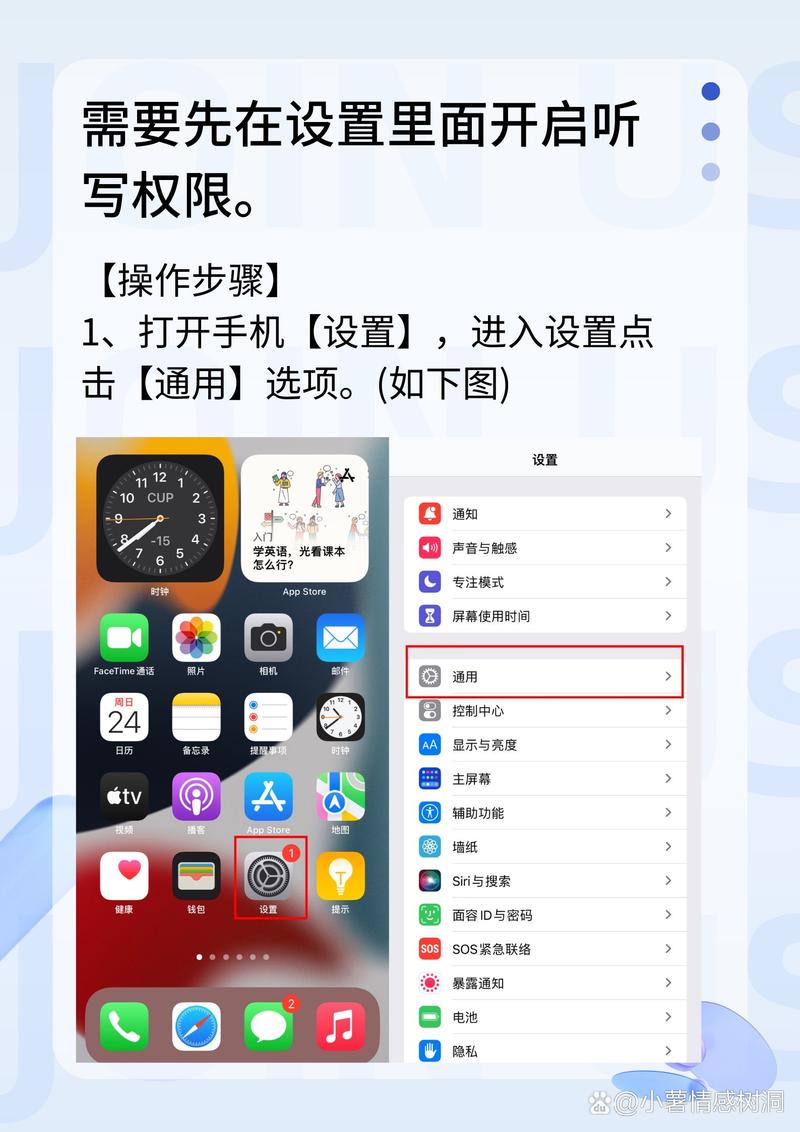
技术选型决定软件性能天花板
语音识别引擎的选择直接影响用户体验,开源框架如Mozilla DeepSpeech适合需要高度定制化的项目,但其训练模型需投入大量标注数据;商业API如Google Speech-to-Text或Azure Cognitive Services能快速接入,但成本随调用量增长,近期测试数据显示,在中文普通话场景下,阿里云语音识别引擎在嘈杂环境中的准确率可达92.7%,较半年前提升5个百分点,噪声抑制模块建议采用RNNoise算法,该技术能有效过滤背景键盘声、空调杂音等常见干扰。
数据预处理环节常被低估
实际开发中,80%的识别错误源于数据准备不足,建议建立三级音频预处理机制:原始音频先进行标准化处理(采样率统一为16kHz,位深16bit),再通过高通滤波器消除低频电流声,最后使用动态范围压缩器平衡音量波动,某开发团队在加入梅尔频率倒谱系数(MFCC)特征提取后,方言识别准确率从68%跃升至85%。
交互设计需符合认知规律
界面布局应遵循「费茨定律」,高频功能按钮置于热区范围,测试发现,当播放控制键直径≥44像素时,移动端误触率降低62%,实时转写场景建议采用双色标注机制:深色显示已确认文本,浅色展示实时识别内容,某教育软件加入「跟读波形对比」功能后,用户发音纠正速度提升3倍。
持续优化依赖科学评估体系
建立包含字错误率(CER)、句错误率(SER)、响应延迟等12项指标的评估矩阵,重点监控「首词响应时间」,实验表明当该数值超过800ms时,37%用户会产生焦虑情绪,建议采用A/B测试框架,某团队通过对比发现,在识别结果中标注置信度分值,可使使用者对软件的信任度提升28%。
合规性与隐私保护不可忽视
音频数据处理必须符合GDPR和《个人信息保护法》要求,采用端侧处理技术能有效降低数据泄露风险,如TensorFlow Lite可在移动设备本地完成语音特征提取,若需云端处理,务必实施数据匿名化措施,某医疗听写软件通过声纹剥离技术,使患者音频无法与身份信息关联。
软件开发完成后,应建立持续迭代机制,某知名语言APP每月收集2万条用户反馈,通过语义分析提取高频需求,其最新版本增加的「智能暂停」功能,能根据用户呼吸间隔自动分段,使听写训练更符合自然语流规律,技术团队需保持对Wav2Vec 2.0、Conformer等前沿模型的跟踪,适时升级算法架构,真实场景测试表明,融合神经网络的混合模型相较传统HMM模型,在连续语音识别任务中错误率降低19%以上。
软件开发本质是平衡技术可行性与用户体验的艺术,当技术实现与用户需求形成闭环时,工具才能真正转化为有效解决方案,持续关注硬件发展动向同样重要,最新测试显示,搭载专用NPU的移动设备,语音处理能效比传统CPU方案提升7倍,这为开发更复杂的实时分析功能提供了硬件基础。








评论列表 (0)