准备工作
安装采集软件前,需明确目标与需求,无论是用于数据分析、内容聚合还是其他用途,选择合适的工具是关键,以下流程以通用型采集软件为例,涵盖主流系统(Windows/macOS/Linux),确保步骤清晰、操作安全。
第一步:选择适合的采集软件
市面常见采集软件可分为两类:
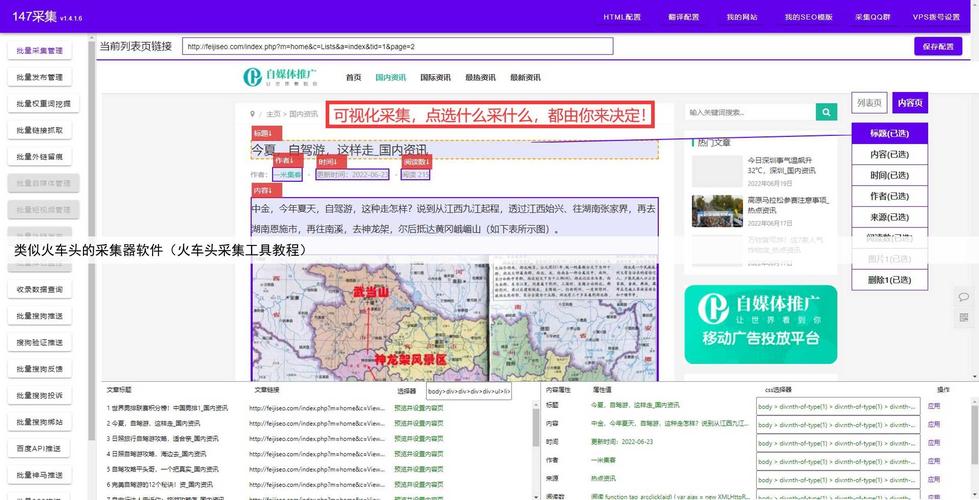
1、开源工具(如Scrapy、Octoparse):免费、灵活,适合有一定技术基础的用户。
2、商业软件(如八爪鱼、火车头):界面友好,功能集成度高,适合快速上手。
建议:优先选择官网下载渠道,避免第三方平台可能携带的恶意程序。
第二步:系统环境检查
不同软件对运行环境有不同要求:
Windows系统:检查.NET Framework版本(部分软件依赖此环境),更新至最新补丁。
macOS/Linux:确认Python或Java环境是否安装(开源工具常依赖编程语言支持)。
操作示例(以Python环境为例):
1、打开终端(macOS/Linux)或命令提示符(Windows)。
2、输入python --version,若显示版本号即环境正常;若无,需前往Python官网下载安装。
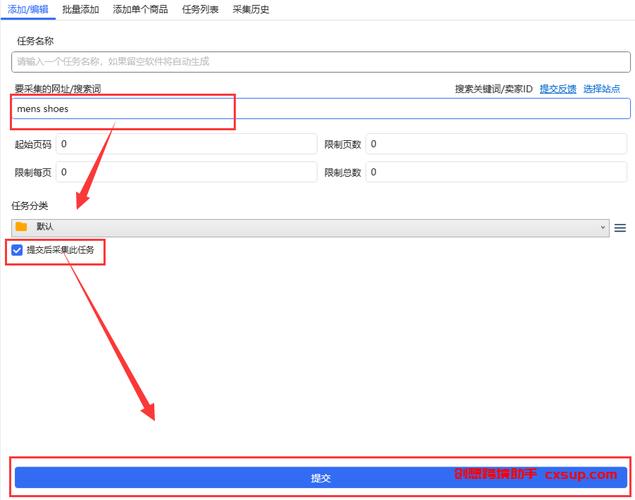
第三步:安装采集软件
以开源工具Scrapy为例,演示安装流程:
1、安装Python(如未完成):
- 访问Python官网,下载对应系统版本。
- 勾选“Add Python to PATH”,完成安装。
2、通过pip安装Scrapy:
- 打开终端/命令提示符,输入:
pip install scrapy - 等待安装完成,输入scrapy version 验证是否成功。
商业软件安装提示:
- 下载安装包后,双击运行,按向导提示完成。
- 部分软件需输入许可证密钥,请提前购买并保存。
第四步:基础配置与测试
安装完成后,需进行初步配置:
1、设置代理(如需):
- 部分网站限制高频访问,需在软件中配置IP代理池,防止被封禁。
2、定义采集规则:
- 输入目标网址,通过可视化界面或代码指定需抓取的数据字段(如标题、价格)。
3、试运行:
- 启动任务,观察日志输出,若报错,检查网络连接或规则逻辑。
常见问题处理:
依赖缺失:根据错误提示,通过包管理器(如pip)安装缺失库。
权限不足:以管理员身份运行软件或终端。
第五步:安全与合规注意事项
1、遵守网站协议:
- 查看目标网站的robots.txt文件,确认允许爬取的目录与频率。
2、数据存储规范:
- 敏感信息需加密处理,避免本地存储泄露风险。
3、反爬策略应对:
- 设置合理请求间隔(如2-5秒/次),模拟真人操作。
观点与建议
采集软件的安装仅是第一步,长期稳定运行需持续优化规则与维护环境,对于非技术用户,商业软件能降低学习成本;开发者则可深入开源工具,定制个性化功能,无论选择哪种方案,始终将合法性与数据安全置于首位,避免因技术滥用导致法律风险。








评论列表 (0)