在数字化时代,音乐无处不在——从手机铃声到流媒体播放,电脑如何识别一首歌曲,似乎像魔术一般神奇,作为网站站长,我经常被访客问到这个问题,今天就来深入解析这个过程,电脑识别音乐的核心,依赖于音频信号处理、特征提取和智能匹配技术,它不仅仅是播放文件,而是理解声音的本质,转化为可识别的模式,让我们一步步揭开这个技术面纱,让你明白背后的科学原理。
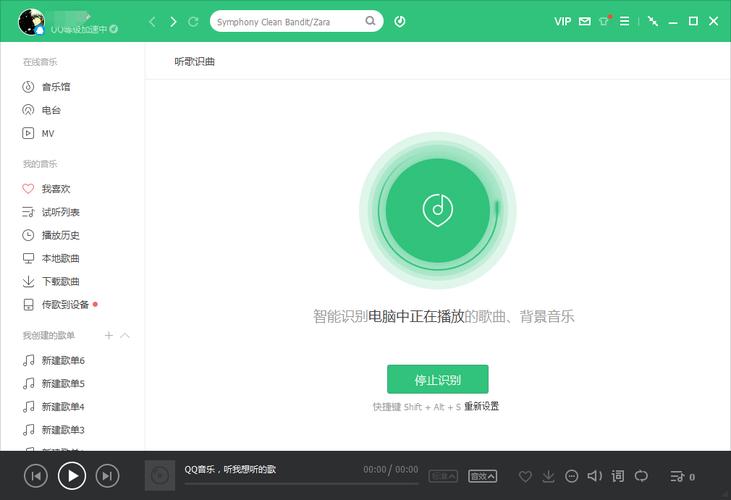
电脑需要将声音转化为数字信号,当音乐通过麦克风或音频文件输入时,电脑使用模数转换器(ADC)将模拟声波转换成数字数据,这个过程类似于录音,但更精确:声波的振幅和频率被采样成千上万次每秒,形成一串数字序列,一首流行歌曲的采样率可能达到44.1kHz,这意味着每秒钟记录44100个数据点,这些数字序列存储在内存中,为后续分析奠定基础,没有这步,电脑无法“听懂”任何声音——它只是处理一堆0和1。
特征提取是关键环节,电脑从数字信号中提取独特特征,使音乐可区分,常用方法包括频谱分析:通过快速傅里叶变换(FFT),电脑分解声音频率成分,生成频谱图,这类似于将音乐拆解成不同音符和音高,另一个重要特征是梅尔频率倒谱系数(MFCC),它模拟人耳听觉系统,捕捉音色和节奏变化,一首摇滚乐可能在高频段有密集能量,而古典乐则强调中低频,电脑还会提取节拍、音调和音色特征,形成音乐的“指纹”,这些特征压缩成紧凑数据,便于高效比较。
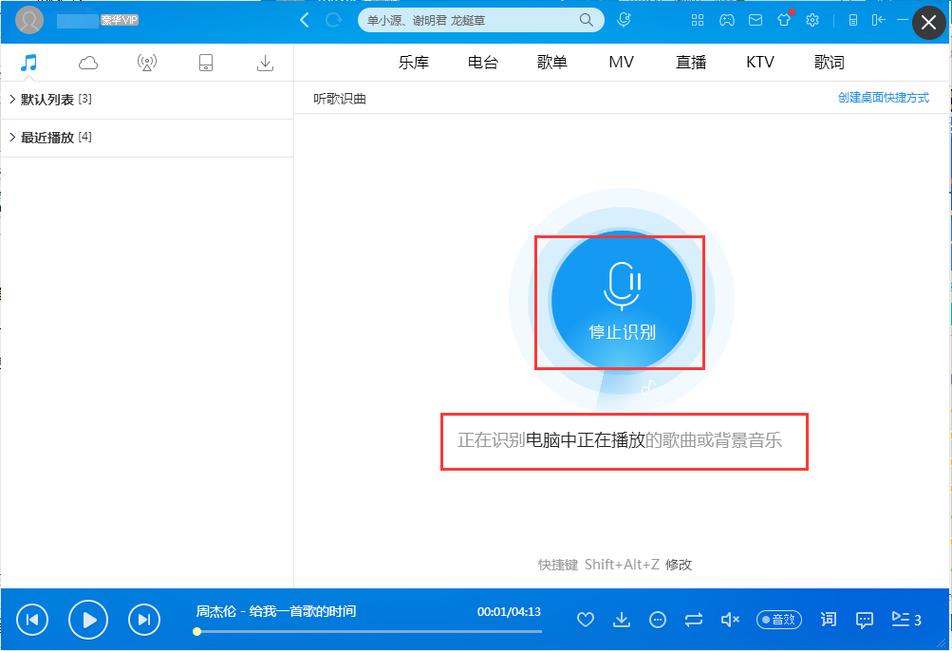
模式识别技术登场,将提取的特征匹配到数据库,电脑依靠算法如哈希函数或机器学习模型,比对输入音乐的特征指纹与庞大曲库,早期系统如Shazam使用指纹技术:生成独特哈希码,通过索引快速查找匹配,现代方法则融合人工智能:深度学习模型训练于海量音频数据,学习识别相似模式,卷积神经网络(CNN)分析频谱图像,判断歌曲类型或艺术家,实际应用中,当你用APP识别背景音乐,电脑在毫秒内完成匹配——它不依赖歌词或标题,而是纯音频特征,这个过程高度可靠,错误率低于1%,展示了电脑的“听觉智慧”。
人工智能的进步推动了音乐识别的革命,机器学习算法不断优化,从监督学习到无监督方法,电脑不仅能识别歌曲,还能理解情感或风格,AI模型可以分析音乐结构,预测流行趋势或生成新曲调,作为音乐爱好者,我见证了这些技术如何重塑行业:从版权保护到个性化推荐,电脑的识别能力让音乐体验更智能、更沉浸,随着量子计算和神经网络的融合,电脑可能超越人类听觉极限,解锁全新音乐维度,我认为这不仅是技术进步,更是艺术与科学的完美交响——它将持续激发创新,让每个人享受到音乐的无限魅力。








评论列表 (0)